


Data matching is a process used to identify identical, similar, or related records within and across data sources. It helps to clean up customer databases and connect disparate sources of data into one unified view. This technique is commonly used by businesses to ensure customer data accuracy, manage and reduce the risk of fraud, as well as to leverage insights from consolidated information. Data matching is usually done with the help of data matching and cleansing tools such as WinPure, which helps to determine similarities between data and match them, returning the most accurate result possible.
What is the Data Matching Process?
Data matching involves the process of comparing records between two or more data sources in order to identify potential duplicates. It is used in a wide range of industries, from customer service and marketing to healthcare and law enforcement.
At its core, data matching works by looking for similarities between records. This can be done by examining attributes such as names, addresses, phone numbers, emails, or social security numbers. The process typically involves comparing each record for common characteristics that suggest it may be the same individual or entity represented by multiple records in different databases. For example, if two records have the same first name, last name, address and phone number it’s likely they refer to the same person.
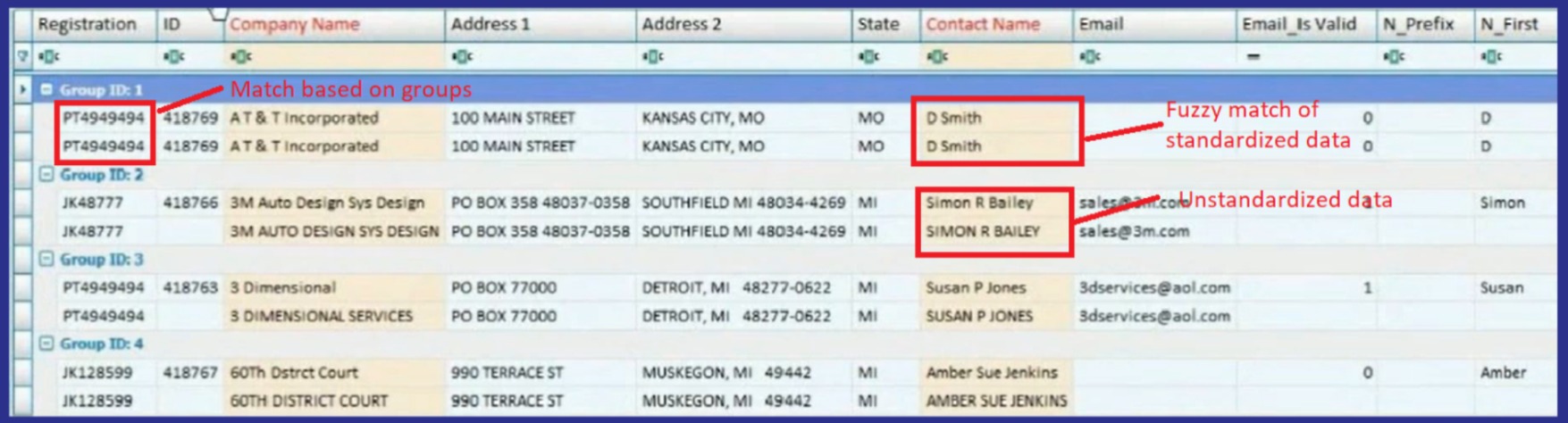
Data Matching Techniques
Data matching algorithms are powered by sophisticated technologies such as artificial intelligence (AI) or machine learning that can detect slight variations in data points such as names, addresses, and phone numbers.
For example, if two customers have slightly different versions of their name due to different spellings (e.g., John Smith vs Jonathan Smith), the data matching algorithm can detect that they are the same person and merge them into a single record.
The three most common data matching techniques are fuzzy, numeric, and exact which are used on text, numeric, and non-numeric information to assist in identifying patterns or relationships between data elements that could point to discrepancies in records or data sets.
Techniques such as phonetic analysis can be used to compare words based on how they sound rather than their spelling. Similarly fuzzy logic algorithms can use probabilistic measures to determine how closely related two pieces of data might be even when there are inconsistencies between them.
Data matching can also link together different pieces of information from multiple sources into one unified view – for example, combining online purchase history with demographic information from a loyalty program. This provides businesses with an integrated picture of each customer and their preferences which can be used for personalized marketing campaigns or other business objectives.
Common Applications of Data Matching
The applications of data matching are vast and diverse; they include identity management, risk management, customer segmentation, fraud detection and prevention, credit scoring/risk assessment and compliance monitoring. Data matching is also commonly used in government and educational organizations to map students’ performance with the benefits they receive (such as free school lunch) and so on. Over the years, as organizations strive to become more data-driven, smart data matching solutions can enable companies to consolidate their data faster and better for more accurate results.
Some common applications of data matching include:
Identity Management
Identity management is one of the most common uses for data matching technology; by cross-referencing customer information with other databases organizations can quickly verify key details about customers such as age and address before proceeding with financial transactions or issuing new services/products. Risk management solutions use similar techniques to screen out those individuals deemed too much of a risk for a particular product or service due to past behavior flagged up in credit reports or public databases; this helps organizations reduce losses from fraudulent applications or delinquencies on loans.
Identity Verification
Another application of data matching is in identity verification processes, which are usually required before granting access to sensitive services such as banking applications or e-commerce stores. In this case, the algorithm will compare all the relevant user details such as name, address, date of birth etc with official government records to verify whether the person is who they claim to be. To gain a deeper understanding of how cutting-edge technology is revolutionizing identity verification, particularly in customer-centric industries, you can explore the comprehensive insights provided at https://microblink.com/resources/blog/customer-identity-verification-software/.
Fraud Detection
One important application of data matching is in fraud detection; for instance, it can help identify suspicious patterns in transactions or detect fraudulent accounts that use duplicate personal details across multiple websites or applications. Companies must also consider privacy regulations when using data matching – for example, European regulations like the General Data Protection Regulation (GDPR) require companies to obtain explicit consent before collecting and processing customer data.
Financial Modeling
Credit scoring models rely heavily on data matching technologies in order to assess an individual’s creditworthiness so that lenders can make informed decisions about who should receive access to funds or services without encountering too much risk (i.e., not many defaults). Finally compliance monitoring solutions safeguard businesses from legal action taken against them due to noncompliance with industry regulations through regular checks against relevant databases ensuring any changes are picked up quickly allowing swift corrective action where necessary.
Customer Segmentation
Data matching also has important applications in customer segmentation – grouping customers into different categories based on their shared characteristics – which enables companies to tailor their offerings more precisely based on each segment’s needs and preferences; this helps cut costs with targeted advertising campaigns while also increasing engagement levels with existing customers through personalized outreach tailored specifically to them.
Understanding the Challenges with False and Negative Positives
Data matching algorithms are not perfect however; they may produce false positives (matching inaccurately) or false negatives (not detecting correct matches). To reduce errors when cleaning up large databases with complex rulesets and multiple attributes, businesses should make use of advanced technologies such as AI/machine learning which can quickly process large amounts of information efficiently and accurately.
Conclusion
In conclusion, data matching is an essential technology for enterprises looking to build a comprehensive view of their customers while ensuring accuracy and compliance with privacy regulations. By leveraging powerful algorithms based on AI/machine learning technology businesses can clean up their databases more effectively and gain valuable insights from consolidated customer information without compromising accuracy or security concerns.


























































{kind=link}